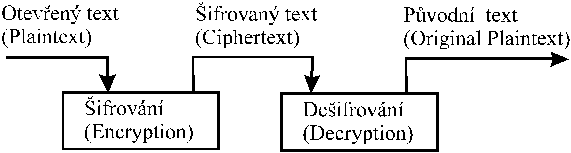
Sifrovani [Encryption, encoding, enciphering]
je proces, pri kterem je zprava zakodovana
tak, ze jeji obsah neni zrejmy
Desifrovani [Decryption, decoding, deciphering]
je pak proces opacny
Kryptosystem [Cryptosystem] je system
umoznujici sifrovani a desifrovani
zprav.
Otevreny text [Plaintext] - originalni
tvar zpravy
Sifrovany text, sifra [Ciphertext] - zakodovany
tvar zpravy
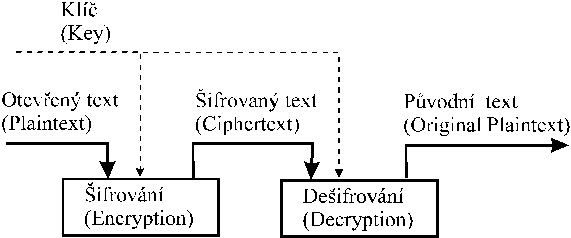
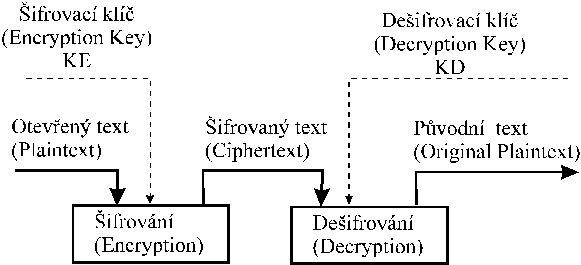
Formalni zapis: (C - sifra, P - otevreny text, E,D - (de)sifrovaci algoritmus, K - klic )
sifrovani:
C = E(P) resp. C = E(K,
P) , C = E(KE, P)
desifrovani:
P = D(C) resp. P = D(K,
C), C = D(KD, P)
korektnost:
P = D(E(P))
Kryptografie [Cryptography] vyuziva sifrovani k ukryti dat
Kryptoanalyza [Cryptoanalysis] se zabyva hledanim zpusobu jak sifrovane zpravy neautorizovane desifrovat (encryption break)
Kryptologie [Cryptologie] - je veda o sifrovani obecne a zahrnuje tedy obe predchozi odvetvi
Sifrovaci algoritmus muze byt zlomen - znamena, ze s dostatkem casu a prostredku muze byt nalezen zpusob jak desifrovat jim zasifrovane zpravy bez znalosti klice.
Prakticky nezlomitelny - je znam postup jak se domoci otevreneho textu, ale ne v rozumnem case (se soucasnou technologii a znalostmi! ).
Casto pouzivana reprezentace znaku (vypocty jsou modulo n = 25)
znak A B C D E F G H I J K L M kod 0 1 2 3 4 5 6 7 8 9 10 11 12 znak N O P Q R S T U V W X Y Z kod 13 14 15 16 17 18 19 20 21 22 23 24 25
- substitucni sifry, pouzivajici jednu substitucni tabulku, ktera kazdemu znaku abecedy prirazuje jiny
Caesarova sifra: ci=E(pi)=pi+3
Otevreny text: ABCDEFGHIJKLMNOPQRSTUVWXYZ Sifrovany text: defghijklmnopqrstuvwxyzabc
Otevreny text: ABCDEFGHIJKLMNOPQRSTUVWXYZ Sifrovany text: keyabcdfghijlmnopqrstuvwxz
Kryptoanalyza monoalfabetickych sifer - vyhledavani typickych shluku znaku pro dany jazyk, typickych prvnich/poslednich znaku slov a cetnost vyskytu jednotlivych znaku (frekvencni analyza)
nevyhodou monoalfabetickych substituci je, ze odrazeji
rozlozeni pravdepodobnosti jednotlivych znaku
pouzitim vice substitucnich tabulek polyalfabeticke
substituce dosahuji rovnomerneho rozlozeni
pravdepodobnosti vyskytu jednotlivych znaku v sifrovanem textu
predpokladejme k substitucnich tabulek
pak znak pik+j je sifrovan pomoci j-te
tabulky
je prikladem polyalfabeticke substituce
sifruje se napr. pomoci klice:
0 1 2
01234567890123456789012345
abcdefghijklmnopqrstuvwxyz
A abcdefghijklmnopqrstuvwxyz 0
B bcdefghijklmnopqrstuvwxyza 1
C cdefghijklmnopqrstuvwxyzab 2
D defghijklmnopqrstuvwxyzabc 3
E efghijklmnopqrstuvwxyzabcd 4
F fghijklmnopqrstuvwxyzabcde 5
G ghijklmnopqrstuvwxyzabcdef 6
H hijklmnopqrstuvwxyzabcdefg 7
I ijklmnopqrstuvwxyzabcdefgh 8
J jklmnopqrstuvwxyzabcdefghi 9
K klmnopqrstuvwxyzabcdefghij 10
L lmnopqrstuvwxyzabcdefghijk 11
M mnopqrstuvwxyzabcdefghijkl 12
N nopqrstuvwxyzabcdefghijklm 13
O opqrstuvwxyzabcdefghijklmn 14
P pqrstuvwxyzabcdefghijklmno 15
Q qrstuvwxyzabcdefghijklmnop 16
R rstuvwxyzabcdefghijklmnopq 17
S stuvwxyzabcdefghijklmnopqr 18
T tuvwxyzabcdefghijklmnopqrs 19
U uvwxyzabcdefghijklmnopqrst 20
V vwxyzabcdefghijklmnopqrstu 21
W wxyzabcdefghijklmnopqrstuv 22
X xyzabcdefghijklmnopqrstuvw 23
Y yzabcdefghijklmnopqrstuvwx 24
Z zabcdefghijklmnopqrstuvwxy 25
zakladem je urceni poctu pouzitych substituci, dale dokument rozdelime na casti, sifrovane stejnou substituci a na tyto casti pouzijeme postupy analyzy monoalf. sifer
urcovani poctu pouzitych substituci:
pokud se v otevrenem textu vyskytuje k-krat stejny retezec znaku a k sifrovani bylo pouzito n substituci, ktere se cyklicky stridaji, bude dany retezec zasifrovan priblizne k/n krat stejne.
oznacme Freqi pocet vyskytu symbolu i ve zprave.
Index koincidence IC definujeme
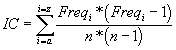
Pokud ma odpovidajici otevreny text rozlozeni znaku blizke normalu, lze z IC usuzovat na pocet pouzitych substituci.
# substituci 1 2 3 4 5 10 >10 IC 0.068 0.052 0.047 0.044 0.044 0.041 <0.038
slozitost analyzy polyalfabetickych sifer roste s poctem pouzitych substituci. -> co treba pouzit kazdou substituci jen jednou
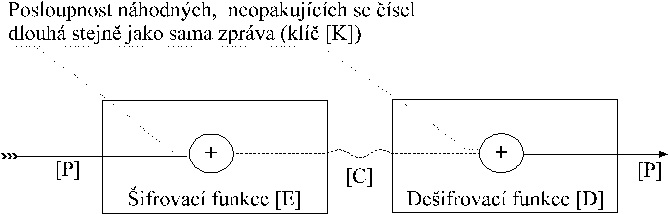
Dlouhe sekvence nahodnych cisel
mohou byt pouzity namisto klicu pro one-time pad
systemy
Generatory nahodnych cisel
je nutne pouzivat vhodne generatory
pracujici na zaklade mereni skutecne
nahodnych velicin
bezne pocitacove generatory jsou nevhodne
mozna implementace one-time pad-u
tssohoa tssohoa niwhaasolrsto niwhaasolrsto