V podstate ide o pseudo-nekontrolované učenie. Spočíva v tom, že FF NN
sú predkladané na vstup a výstup tie isté vzorky. Uvažujme o topológii
FF NN v tvare M-N-M, kde
a väčšinou .
Príklad takejto
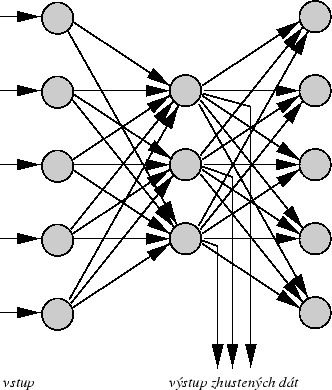
topológie je na obrazku 6.1. Takáto NN sa dá vhodne využiť ma
kompresiu dát. Je použitý klasický BP prístup, ale s tým, že na vstup a výstup
dodávame tie isté dáta. Zhustené dáta potom môžeme získať na skrytej vrstve
o veľkosti N. Tento prístup nám šikovne zabezpečuje aj možnosť rekonštrukcie
dát do pôvodnej formy. Teda postup je triviálny :
Obrázok 6.1:
Zhusťovanie dát z M na N
naučíme NN podľa BP s tým, že ponúkame na vstup trénovacie data
(predstavujú množinu všetkých možnosti), ktoré môžu v dátach nastať a také
isté dáta očakávame na výstupe. Snažíme sa dostať do stavu, keď NN vie
spoľahlivo realizovať celý proces a SV sa už nemenia, teda GS.
potom sme v stave, keď môžeme spoľahlivo realizovať kompresiu dát
a získať zhustené dáta zo skrytej vrstvy
tým máme zabezpečenú aj spätnú rekonštrukciu dát.
Tento jednoduchý prístup sa zdá byť veľmi efektívny pre spomínanú kompresiu
dát.