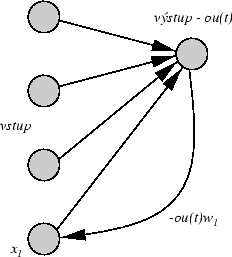
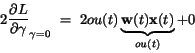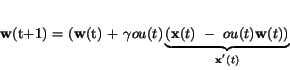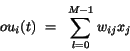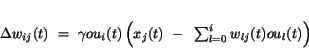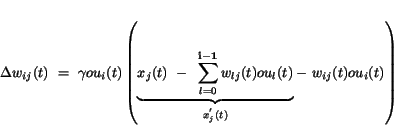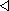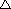Majme jednoduchú NN s n vstupmi a jedným výstupným neurónom
(viď obr. 5.9) Nech výstupný neurón je lineárneho typu, teda
(5.17)
Obrázok 5.9:
Priklad NN pre hľadanie prvého hlavného komponentu
Predpokladajme Hebbove synapsie medzi neurónmi, teda je zrejmé, že
adaptačné pravidlo bude mať tvar5.8
(5.18)
čo v konečnom dôsledku ovplyvňuje novú hodnotu SV v
iterácii
(5.19)
pre
.
Problém vzorca (5.19) spočíva v tom, že pre
neúmerne rastie, čo pri reálnych systémoch spôsobuje
problémy. Predísť tejto saturácii môžeme určitou formou normalizácie
výrazu (5.19). Oja navrhol nasledovnú formu (výrazy sú vo vektorovom
tvare):
Funkciu
rozvinieme do Taylorovho radu a členy
a vyššie mocniny
pri predpoklade malého
zanedbajme.5.9 Potom pre druhý člen rozvoja
dostaneme (predpokladáme
) :
(5.22)
čo po úprave znamená, že
(5.23)
teda samotný Taylorov rozvoj
má konečný tvar pri zanedbaní
členov s vyššími mocninami
(5.24)
ale v podstate my máme v zmysle situácie v (5.20) tvar
(5.25)
ktorý keď rozšírime výrazom
dostaneme
(5.26)
Pretože
môže byť zvolené dostatočne malé,
,
teda menovateľ sa blíži k 1 a môžeme písať
(5.27)
ak to dosadíme späť do vzorca (5.20) a znova zanedbáme
dostaneme
(5.28)
čo v konečnom dôsledku znamená
(5.29)
kde je zrejmé, že
(5.30)
teda nová hodnota SV sa vypočíta ako
(5.31)
kde
predstavuje tzv. efektívny vstup do výstupného
neurónu. Teda doteraz uvedený proces môžeme zhrnúť do nasledovných bodov:
nárast SV na základe vstupu x(t)
pomyselná spätná vazba
,
ktorej úloha je
kontrolovať nárast SV a tak stabilizovať činnosť NN. Táto pomyselná spätná
väzba sa nazýva tiež zabúdací faktor.
Vzorec (5.29) sa tiež nazýva Ojove adaptačné pravidlo zmeny
SV. Po nájdení GS NN dostaneme v hodnotách w vektora prvý hlavný
komponent. To, že NN s takýmto adaptačným pravidlom určite nájde svoju GS,
nájdeme popísané v [5].
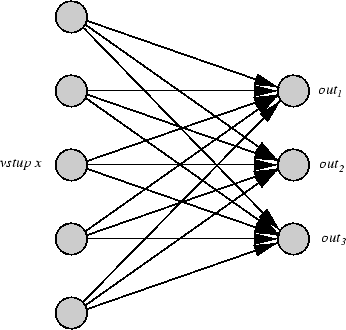
Rozšírme teraz náš zámer o hľadanie ďalších hlavných komponentov zhusteného
priestoru komponentov. Teda majme jednoduchú NN s M vstupmi a N výstupmi
viď obr. 5.10 súčasne platí, že
a výstupné neuróny sú
lineárneho typu. Z výhodných dôvodov si označme jednotlivé neuróny
vo vstupnej vrstve nasledovne vstupné
a výstupné
. Potom výstup v neurónu "i" vypočítame ako
(v skalárnom vyjadrení)
Obrázok 5.10:
NN pre vypočet 3 hlavných komponentov
(5.32)
potom dostaneme vo vzorci (5.33)
tzv. zovšeobecnený tvar Hebbovho adaptačného
pravidla v tvare5.10
(5.33)
Ak do vzorca (5.33) dosadíme ,
tak dostaneme vzorec pre adaptačné
pravidlo, ktoré sme už odvodili vo vzťahu (5.30).
Teraz opäť pre následnú výhodnosť si vzorec (5.33) do tvaru
(5.34)
Teraz v podstate dostávame situáciu, keď máme jedno adaptačné pravidlo, kde
sa efektívny vstup do jednotlivých výstupných neurónov mení. V rámci
jednej učebnej procedúry sa nám podľa (5.33) budú meniť SV rôzne, podľa
toho, ku ktorému z výstupných neurónov smerujú (index "i"). Ak chceme
nájsť všetkých N hlavných komponentov, potom vlastne hľadáme
1.
prvý hlavný komponent potom
zo vzorca (5.34)
má tvar ()
(5.35)
2.
druhý hlavný komponent ()
(5.36)
3.
tretí hlavný komponent ()
(5.37)
4.
atď
Takýmto spôsobom je možné postupne vypočítať jednotlivé hlavné komponenty
dát a realizovať ich zhustenie. Existuje ešte verzia učiaceho algoritmu,
ktorá uvažuje o laterálnych prepojeniach. Tak isto aj pre prípad nelineárnych
neurónov bol vyvinutý Ojo-om podobný postup.