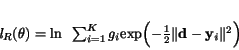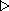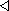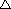Neurónovú sieť možno chápať aj ako prostriedok pre štatistické modelovanie a
predikciu. Z tohto hľadiska je činnosť naučenej neurónovej siete úspešná, ak
modeluje proces, pomocou ktorého boli učiace vzorky generované. Veľkosť
chyby v procese učenia preto nemôže byť postačujúcim ukazovateľom kvality
naučenia siete.
Najvšeobecnejší a kompletný popis vzoriek učiacej množiny je možný podľa funkcie rozdelenia
ich pravdepodobnosti
[21].
Cieľom učiaceho algoritmu aplikovaného na danú architektúru je modelovanie
pravdepodobnostného rozdelenia množiny učiacich vzoriek
alebo aj maximalizácia funkcie rozdelenia pravdepodobnosti
.
Podľa [21] môže byť maximalizácia logaritmickej pravdepodobnostnej funkcie
interpretovaná ako minimalizácia chybovej funkcie
doprednej siete
(4.6)
Ak
predstavuje nepodmienenú pravdepodobnosť vstupu a
je podmienená pravdepodobnosť výstupu, ktorá je podmienená
vstupným vektorom x, potom sa funkcia rozdelenia pravdepodobnosti
vypočíta ako súčin hodnôt týchto dvoch pravdepodobností
(4.7)
Pri ďalšom odvodzovaní učiaceho algoritmu je výhodnejšie pracovať s
prirodzeným logaritmom výrazu (4.7). Je tak možné urobiť, pretože funkcia
logaritmus je monotónne rastúca na celom definičnom obore.
Logaritmická pravdepodobnostná funkcia je definovaná nasledovne:
(4.8)
Hodnota pravdepodobnostnej funkcie závisí od množiny hodnôt voľných parametrov
siete .
Typ podmienenej pravdepodobnosti
závisí od typu úlohy, pre ktorý je
modulárna sieť určená.
Regresia: Učiace údaje sú spojité z oboru reálnych hodnôt. Rozdelenie
pravdepodobnosti výstupných hodnôt je možné opísať pomocou Gaussovho rozdelenia pravdepodobnosti
(4.9)
d
- požadovaný výstupný vektor hodnôt
y
- výstupný vektor hodnôt expertnej siete
- matica kovariancií
- počet neurónov expertnej siete
Klasifikácia: Výstupné hodnoty klasifikátora nadobúdajú diskrétne hodnoty. Podľa
[21] je v takom prípade potrebné pre ich opis použiť Bernoulliho rozdelenie
pravdepodobnosti.
(4.10)
- požadovaná výstupná hodnota -teho neurónu
expertnej siete
- výstupná hodnota -teho neurónu expertnej siete
- počet neurónov expertnej siete
Za predpokladu, že kovariančná matica
vo výraze (4.9)
je jednotková, je možné
hodnotu argumentu funkcie
v Gaussovskom rozdelení pravdepodobnosti
vypočítať ako Euklidovskú normu vektora.
(4.11)
Dosadením výrazu (4.11) do (4.7) pre všetky
expertné siete sa získa
vzorec pre výpočet celkovej podmienenej pravdepodobnosti.
(4.12)
Dosadením výrazu (4.12) do (4.8) pri zanedbaní konštanty
sa získa konečný tvar logaritmickej
pravdepodobnostnej funkcie pre regresiu.
(4.13)
Toto rozdelenie pravdepodobnosti je uvedené v [5] pod názvom
Gaussov zmesový model. (Gaussian mixture model).
Logaritmickú pravdepodobnostnú funkciu pre klasifikáciu možno vyjadriť
podobne v tvare
(4.14)
Pravdepodobnostné funkcie (4.13) a (4.14) budú ďalej základom pre
odvádzanie učiacich algoritmov pre regresiu a klasifikáciu.
![\begin{displaymath}
\it p({\bf d\vert x}) = \frac{\rm 1}{\sqrt[q]{2\pi}\sqrt{\...
...\bf d-y})^{\it T}
{\bf\Lambda^{\rm -1}}
({\bf d-y}) \Bigr )
\end{displaymath}](img261.gif)
![\begin{displaymath}
\it p({\bf d\vert x}) = \frac{\rm 1}{\sqrt[q]{2\pi}}
\ens...
...gl ( -\frac{\rm 1}{\rm 2} \Vert{\bf d-y}\Vert^{\rm 2} \Bigr )
\end{displaymath}](img267.gif)
![\begin{displaymath}
\it p({\bf d\vert x}) = \frac{\rm 1}{\sqrt[q]{2\pi}}
\ens...
...rac{\rm 1}{\rm 2} \Vert{\bf d-y_{\it i}}\Vert^{\rm 2} \Bigr )
\end{displaymath}](img268.gif)