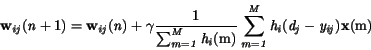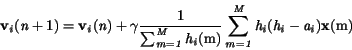Použitie modulárnej architektúry predpokladá zvládnutie problému rozdelenia
jednotlivých učiacich vzoriek medzi expertné moduly a sformovanie
celkového výstupu. Algoritmus Expectation Maximisation -
EM je alternatívnym riešením tohto problému k už uvedenému spôsobu metódou
najstrmšieho vzostupu pravdepodobnostnej funkcie.
EM algoritmus vznikol v roku 1977 a bol pôvodne využívaný pre nekontrolované
učenie v kontexte zhlukovania. Veľmi rozšírené je jeho použitie v oblasti
matematiky. Použitie pre kontrolované učenie spolu s modulárnou
architektúrou uvádzajú Jacobs a Jordan v [8]. Ide o úpravu voľných
parametrov siete za účelom maximalizácie pravdepodobnostnej funkcie pomocou
algoritmu EM.
Nech
je množina binárnych vektorov
,
pričom
je počet vzoriek trénovacej množiny .
Každý vektor množiny
je -prvkový, pričom
je počet expertných modulov. Prvok
ak je -ta vzorka generovaná -tym expertným modulom.
Pridaním množiny
k trénovacej množine
vznikne nová
množina .
Takýmto rozšírením trénovacej množiny vznikne
kompletná pravdepodobnostná funkcia
.
Ak by bola množina
naozaj známa, optimalizácia kompletnej
pravdepodobnostnej funkcie by bola jednoduchšia. Keďže množina
je
neznáma, EM algoritmus je rozdelený na dve časti. Najprv sa nájde očakávaná
hodnota kompletnej pravdepodobnostnej funkcie. V druhom kroku sa hľadajú
také hodnoty parametrov ,
ktoré zväčšujú jej hodnotu.
E-krok:
(4.42)
M-krok:
(4.43)
Jacobs a Jordan v [8] uvádzajú, že
zväčšením hodnoty kompletnej pravdepodobnostnej funkcie sa dosiahne aj
zväčšenie hodnoty pôvodnej pravdepodobnostnej funkcie oproti predošlému
kroku výpočtu. Každá iterácia tak zväčší hodnotu
(4.44)
Hodnota pravdepodobnostnej funkcie
sa monotónne zväčšuje
spolu s postupnosťou odhadov parametrov ,
ktoré sú generované EM
algoritmom. To je podľa [8] príčinou konvergencie do lokálneho maxima.
Napriek výhodám oproti metóde najstrmšieho vzostupu nie je EM
algoritmus odolný voči takejto nežiadúcej konvergencii.
Konkrétna implementácia pre úlohy klasifikácie je prevzatá z [20].
Architektúra siete je zhodná s architektúrou podľa Obr. 4.1.
Všetky siete majú v tomto prípade výstupnú funkciu typu softmax. Výstupná
hodnota -teho neurónu -tej expertnej siete je určená vzťahom
(4.45)
Podobne sú určené výstupné hodnoty
neurónov bránovej siete.
(4.46)
Pre všetky expertné moduly potom platí
(4.47)
Hodnota
sa môže interpretovať ako pravdepodobnosť, že -ty modul
klasifikuje aktuálnu učiacu vzorku do triedy .
Waterhouse v [20]
uvádza, že ak aktuálna učiaca vzorka patrí do triedy ,
potom platí
(4.48)
pričom
je aposteriórna pravdepodobnosť, že -ty expertný modul
klasifikuje aktuálnu učiacu vzorku do triedy .
Zanedbávajú sa tým
hodnoty zvyšných neurónov expertného modulu. Je tak možné urobiť, ak sú
výstupné vektory učiacich vzoriek kódované podľa pravidla 1-z-.
Pre úpravu hodnôt vektora váh, ktorý prislúcha -temu neurónu -teho
expertného modulu platí
(4.49)
Pre úpravu hodnôt vektora váh, ktorý prislúcha -temu neurónu bránového
modulu platí
(4.50)
Z uvedených vzťahov vyplýva, že úprava hodnôt váh sa vykonáva iba raz na konci
každého učiaceho cyklu. Pri metóde najstrmšieho vzostupu sa hodnoty váh
upravujú pri prezentácii každej vzorky. Učenie pomocou EM algoritmu je
preto z hľadiska behu v reálnom čase v porovnaní s touto metódou rýchlejšie.
Podľa predpokladov by učenie pomocou EM algoritmu malo byť rýchlejšie aj z
hľadiska počtu učiacich cyklov potrebných na dosiahnutie minimálnej
chyby učenia.