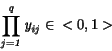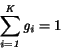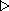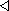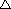Výstupné hodnoty klasifikátora nadobúdajú diskrétne hodnoty. Ich
popis je možný pomocou Bernoulliho rozdelenia pravdepodobnosti.
Pravdepodobnostnú funkciu
potom možno vyjadriť
podľa vzťahu (4.14). Neuróny v expertných a bránovom module nie sú
lineárne. Výstupná hodnota -teho neurónu -teho experného modulu je
určená sigmoidálnou funkciou
(4.35)
Podobne je určená aj aktivačná hodnota -teho neurónu bránového modulu
(4.36)
Výstupné hodnoty
neurónov bránového modulu sú určené nelinearitou typu
softmax, ale bez funkcie exp
(4.37)
Hodnoty
a
spĺňajú nasledujúce podmienky:
(4.38)
Podľa týchto ohraničení sa interpretuje činnosť bránového modulu ako
klasifikácia nad celým definičným oborom aproximovanej funkcie. Takto sa
vstupný priestor vzoriek rozdelí na viacej oblastí. Činnosť expertných modulov
sa interpretuje ako klasifikácia vo vnútri jednotlivých oblastí vstupného
priestoru vzoriek. Na tomto mieste je potrebné podotknúť, že výstupné
vektory učiacich vzoriek sú kódované podľa pravidla 1-z-.
Ak aktuálna
učiaca vzorka patrí do triedy ,
výstupný vektor
potom obsahuje jednu jednotku na pozícii
a zvyšné prvky vektora sú nulové.
Hodnota
sa interpretuje ako pravdepodobnosť, že -ty expertný modul
generoval aktuálnu učiacu vzorku. Hodnota
sa interpretuje ako
pravdepodobnosť, že -ty modul klasifikuje aktuálnu vzorku do triedy .
Ďalší postup odvodenia učiaceho algoritmu je analogický postupu pre
odvodenie učiaceho algoritmu pre regresiu. Rozdiel je pri výpočte
aposteriórnych pravdepodobností
pre potreby klasifikácie.
4.2
(4.39)
Derivácie
a
podľa vektorov váh, ktoré k nim prislúchajú, sú
tvaru
(4.40)
(4.41)
Vzťahy pre úpravu hodnôt váh expertných a bránového modulu sú podobné
vzťahom (4.26) a (4.34).
Zhrnutie učiaceho algoritmu pre klasifikáciu:
1.
Inicializácia.
Hodnoty všetkých váh celej siete sa nastavia na náhodnú hodnotu z malého
intervalu napr. .
2.
Úprava váh.
Úprava váh sa uskutočňuje v
cykloch. V každom cykle sa privedú na vstup
a výstup siete všetky vzorky trénovacej množiny. Každá vzorka je
reprezentovaná dvojicou
.